
¿Por qué esta fórmula? Para contestar esta pregunta, tenemos que recordar algo que dijimos: La regresión logística no es más que un caso particular de modelo lineal generalizado, más conocidos por GLM (Generalized linear models -- no confundir con general linear models--) . En realidad estos modelos fueron planteados como una generalización de la regresión ordinaria por mínimos cuadrados y como forma de englobar diversos métodos como dichas regresiones, modelos de regresión logística o de Poisson etc.
Los GLM son métodos lineales que tratan de estimar el parámetro de una distribución de la familia exponencial (normal, Poisson, Gamma, Binomial) a través de una relación lineal y una función de enlace. Resumiendo, tenemos que un GLM consta de:
- Distribución de probabilidad de la familia exponencial (Normal, binomial, Poisson etc)
- Una relación lineal en la predicción

- Una función de enlace g tal que


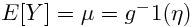
Para contestar estas preguntas, ahora debemos ir al núcleo de la cuestión. La distribución de probabilidad. Ya hemos dicho que se trata de una distribución binomial, pero también hemos señalado que esa binomial es un caso particular de distribución de la familia exponencial. ¿Y eso qué quiere decir?
La familia exponencial es un conjunto de de distribuciones cuyas funciones de densidad/masa tienen un sólo parámetro y pueden expresarse (entre otras muchas equivalentes) de la siguiente manera :

donde,
-θ es el parámetro de la familia exponencial,
-h(x) es una función real ,
-η(θ) es una función de θ. Si η(θ)= θ se dice que la función está expresada en forma canónica.
-c(θ) es otra función, que en este caso desempeña una función de normalización; Una vez se escogen las demás funciones , A sirve para normalizar la densidad y hacer que la suma o integral sobre el dominio valga 1.
-t(x) es otra función real sobre el vector de observaciones, que tiene además relación con la generación de momentos.
Todo este "lío" de funciones y parámetros puede resultar arbitrario y artificial, pero no es así y tiene aún menos de arbitrario que de artificial. Muchas de las distribuciones importantes en probabilidad cumplen esta estructura y tienen como hemos dicho importantes propiedades entre las que se encuentra el poder garantizar la obtención de un único estadístico suficiente para el parámetro poblacional θ en función a la citada función t(x).
Vamos a verlo directamente sobre la distribución binomial:

Podemos descomponer la función de masa de la binomial de la siguiente forma:


y desde aquí ver cómo podemos asimilar:

Por tanto acabamos de demostrar que la distribución binomial pertenece a la familia exponencial. Cuando el parámetro η(θ) , como hemos dicho antes , es θ (el parámetro poblacional de la distribución) decimos que la función está expresada en forma canónica. La función η(θ) , dicho de otra forma, relaciona la forma exponencial con el parámetro de la distribución , la esperanza. En el caso de una binomial, el parámetro es lo que comúnmente se denomina p. Concretando pues , la función sería:
 ,
,también conocida como función logit , y particularmente es la inversa de la función logística en el caso típicamente conocido como sigmoide.
Después de todo esto , volvamos al principio del artículo y veamos la definición de la ecuación del modelo de regresión logística. Efectivamente aparece la función logit relacionada con los términos independientes. Ésa es nuestra función de enlace. En principio , cualquiera puede ser función de enlace , siempre que esté comprendida en el intervalo del parámetro a considerar (en nuestro caso la p de una binomial debe estar siempre entre 0 y 1). De hecho otro caso particular de GLM con la distribución binomial son los denominados modelos probit, que utilizan como función de enlace la inversa de la densidad de una normal estándar. No obstante, se suele utilizar como enlace la función canónica de cada distribución a modelizar , por ser la función que conecta el parámetro natural de la forma exponencial con su esperanza, que es lo que tratamos de modelizar.
Invito a los lectores a buscar los casos particulares de GLM con otras distribuciones, como Poisson , o la densidad normal, y ver las funciones de enlace asociadas. En el caso normal, por ejemplo , resulta que la función de enlace es la identidad, además , claro, aquí no hace falta hacer transformaciones en el dominio de valores de E[Y], ya que pueden pertenecer a toda la recta real...
Llegados a este punto hemos visto de dónde sale la formulación del modelo y su evidente utilidad para estimar proporciones , dado el caso de la distribución binomial. También hemos dado pistas para relacionar todo esto con su generalización a otras distribuciones. Si tenemos una distribución de Poisson , nuestra regresión irá encaminada a estimar su parámetro λ, típicamente el número de eventos ocurridos en una unidad de tiempo. Por cierto, véase que en este caso la función de enlace debe ser >=0..
Lo único que resta es ver cómo estimar los parámetros del modelo. Para el caso que no ocupa, este paso no se resolverá como en la regresión lineal, por el método de mínimos cuadrados, ya que ahí poníamos como hipótesis que la distribución de los errores fuera normal. Ahora no podemos hacer eso, ya que los valores observados Y son discretos y su distribución no es normal.
Los parámetros se hallarán pues a través de la estimación de máxima verosimilitud, que consiste en encontrar los parámetros β que maximizan el log de la función de verosimilitud. Recordemos que la verosimilitud puede entenderse como una función que permite establecer inferencias sobre un parámetro dada una serie de observaciones. Se trata en nuestro caso de tomar en la función de masa el parámetro p como incógnita y el valor x como observado, una "especie de versión no bayesiana" de la estimación en probabilidades condicionadas del enfoque bayesiano. Se toma el logaritmo, ya que hay que encontrar el máximo de esta función y es más sencillo calcularlo a través de logaritmos. Ya sabéis que para maximizar una función hay que tomar derivadas respecto del parámetro y ver que la segunda derivada sea <0.>
Posteriormente, una vez estimados los parámetros , hay que evaluar la bondad del ajuste y la validez del modelo, evaluar colinealidades, etc. También tenemos que decidir acerca del modo de entrada de variables en el modelo, pudiendo , igual que en regresión lineal, realizar opciones forward, backward, stepwise.. aunque de momento lo dejaremos fuera de este artículo, que no tenía la pretensión de explicar el análisis estadístico en sí, del cual se pueden encontrar miles de sitios con muy buena información, sino su origen y el porqué de su formulación. Espero sinceramente haberlo conseguido. Salimos hasta la próxima entrada.



 , donde E representa la esperanza matemática e i la unidad imaginaria. La función característica de la distribución normal vendrá de integrar su densidad multiplicada por
, donde E representa la esperanza matemática e i la unidad imaginaria. La función característica de la distribución normal vendrá de integrar su densidad multiplicada por . Esto resulta (no voy a desarrollar el cálculo) en
. Esto resulta (no voy a desarrollar el cálculo) en 










{kind=link}
{kind=link}